
The Principles of Product Development Flow, пост 1 — введение
Это первый пост про книгу «The Principles of Product Development Flow» Дональда Рейнертсена.
upd. Второй пост: https://artemushanov.ru/?go=all/reynertsen-post-2/

Книга о том, как правильно принимать управленческие решения при разработке продукта.
Читать я ее начал вот так, в этом посте публикую мысли-размышления по поводу основных понятий книги, почерпнутых из введения и пары презентаций на тему.
Разработка продукта и производство продукта #
«Разработка продукта» в книге противопоставляется «производству продукта».
Разработка — это создание «рецепта» продукта. Его можно создать один раз, создавать тот же самый рецепт во второй раз смысла нет — за него не заплатят. Примеры результата разработки: техническая карта овощных консервов; спецификация и техническая карта для смартфона; требования-conops-макеты экранов для софта.
Производство продукта — это процесс выпуска готового продукта в большом количестве по тем самым рецептам. Компания получает деньги за каждый выпущенный экземпляр продукта.
В производстве операции могут быть нормированы, для каждой единицы продукта набор операций одинаковый, можно планировать работу по принципу FIFO и довольно точно прогнозировать срок выпуска партии. Найти косячные места в производстве, особенно физическом, несложно: если перед каким-то производственным участком скопилась куча заготовок, то на этом участке что-то не так. Временные рамки для производства — это часы и дни.
В разработке же набор операций для каждого нового продукта уникален и не похож на операции для предыдущего (или каждого нового варианта продукта — колу в стекле, в пластике и в ЖБ можно считать тремя разными вариантами).
Работы нельзя нормировать, рабочие продукты могут быть практически невидимы, потому что зачастую это просто информация или описания. Такие рабочие продукты Рейнертсен называет Design in Process (DIP). Временные рамки — месяцы и годы.
Один из главных инсайтов:
В разработке продукта нельзя использовать те же управленческие методы, что и в производстве.
В разработке гораздо больше неопределенности, невозможно нормирование, централизация скорее вредит, а принятые на производстве метрики не отражают реальности. Поэтому тойотовская система производства, голдратовская TOC или шесть сигм для разработки не подходят.
В софте «разработку» и «производство» вообще не всегда можно друг от друга отделить.
Что такое «поток» #
Поток (flow) в названии книги — это непрерывное и плавное течение работ и рабочих продуктов в ходе разработки нового продукта. В обратную сторону с той же скоростью текут деньги.
Разработка, говорит книга, должна стучать ровным пульсом, а не аритмией страдать, чтобы и деньги поступали плавно и предсказуемо.
Чтобы обеспечить плавность течения потока, нужно перейти на работу малыми партиями, быстро получать обратную связь по выполненным работам, и ограничивать работу-в-процессе. Приключение на двадцать минут, вошли-вышли.
Двенадцать проблем в продуктовой разработке #
Такая вот картинка из презентации The Principles of product development flow — a summary:

Дальше по порядку
Неудачная квантификация экономики #
Чтобы иметь возможность сравнивать самые разные продуктовые решения между собой и выбирать из них лучшие, предлагается ввести показатель, через который можно оценить любое предлагаемое решение. Решения могут быть разные, самое распространенное — какую фичу/вариант фасовки/новую упаковку брать в работу следующей? На что следует потратить ограниченный ресурс продуктовой команды в следующем рабочем цикле?
В основе метода Рейнертсена — экономический взгляд на продукт. Рейнертсен предлагает все мерять в деньгах, потому что на языке денег можно говорить с любыми стейкхолдерами в компании.
Продуктовые решения должны измеряться в деньгах
Продукт, или продуктовая фича, должны принести N денег за свой жизненный цикл; сам цикл ограничен, можно считать что это величина постоянная, сколько-то лет/месяцев. Любое действие, например, задержка вывода на рынок, влияют на эту эту сумму в плюс или в минус (задержка — в минус). Любое предпринимаемое действие нужно научиться оценивать в этих вот «влияниях» на прибыль продукта и принимать решение на основе них.
Для начала нужно вычислить life-cycle profit продукта — количество денег, которое продукт заработает в течение своего жизненного цикла (далее LCP; пока что мне непонятны тонкости вычисления именно прибыли на ЖЦ продукта, так что разъяснений не будет). Делать это можно любым доступным методом — статистическим, экспертным, математическим и т. п., можно вовлекать людей из продаж и финансов для помощи. Оценка с точностью до трех знаков после запятой тут не нужна, если примерно понятен порядок значения — уже хорошо.
После этого нужно посчитать, какое влияние каждое из доступных нам решений окажет на LCP. Это влияние выражается показателем life-cycle profit impact (далее LCPI). Понять это предлагается через вопрос вида «как скажется на прибыльности продукта задержка выпуска этой фичи (версии, обновления, фасовки и т. п.) на 60 (например) дней?». Ответ на этот вопрос называется «стоимостью задержки» (Cost of Delay, CoD).
В сравнении с интуитивным методом, предлагаемый фреймворк должен показывать более точные результаты. В книге описывается, что интуитивные оценки стоимости задержки одного и того же проекта среди коллег могут различаться в 50 раз: в приведенном примере это был диапазон от 10 000 до 500 000 долларов за двухнедельную задержку.
Стоимость задержки показывает, во сколько нам обходится «лежание» готового рабочего продукта или DIP в очереди на обработку следующим звеном. Например, инженеры за три дня подготовили спецификации на новый продукт и передали в производство для оценки. Оценка займет один день. А производство сможет взяться за эти карты только через две недели — у них завал и куча заявок. В итоге вместо четырех дней техкарты будут подготовлены и одобрены за 14 дней. Если мы знаем стоимость задержки — мы можем понять, сколько денег компания потеряла за время ожидания.
Стоимость задержки нужна, чтобы вычислять: стоимость очередей; стоимость избыточных запасов; выгоду от использования малых партий; оценку снижения вариабельности. Обо всем этом — ниже.
Вот отдельное видео про стоимость задержки: https://vimeo.com/101506552
Шакальский скрин оттуда:
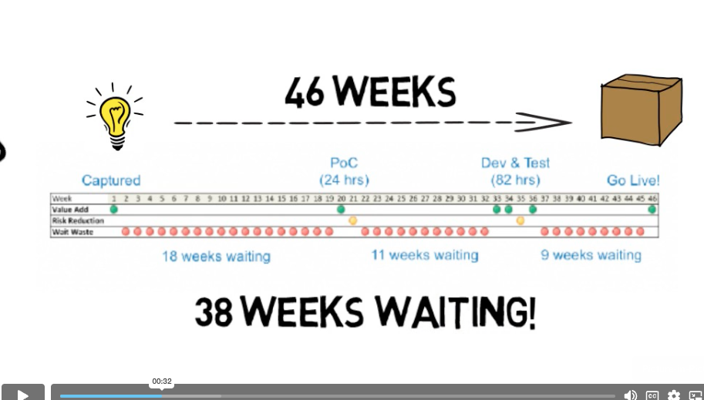
Фича была сделана за 46 недель, при этом 38 недель провела в ожидании своей очереди на каком-то из этапов. То есть чистого времени требовалось примерно 8 недель.
И вот эти очереди — они зачастую невидимы в не-физических производствах.
Поэтому оценивается обычно не полный цикл работы над РП, не сами очереди, а только кусочек цикла, когда над РП идет какая-то работа. Это вот к пунктам про невидимость очередей и фокус на «эффективности».
Если отсутствие фичи стоит нам $200k в неделю, мы недополучили $8 млн за 38 недель ожидания. Если мы это понимаем, то мы мы можем управлять решениями исходя из финансово-экономических предпосылок, а не любых других.
Вкратце: когда мы планируем взять фичу в спринт/релиз, мы должны выбирать ту, у которой выше стоимость задержки.
Слепость к очередям #
Очереди — главная причина проблем в продуктовой разработке. При этом почти никто измерять очереди не умеет (я пока что тоже).
Одна из причин, как мне кажется, это незнакомство в целом с концепцией очереди применительно к управлению проектом; довольно контринтуитивная штука

В изучении очередей Рейнертсен пользовался наработками теории массового обслуживания.
Что такое «очередь»? Это когда у нас есть рабочий продукт в каком-то состоянии, и над ним не ведется работа, он находится в ожидании. Передали фичу из производства в QA — она в бэклоге неделю отлеживается. Передали потом техписателям — еще неделю лежит.
Вот это ожидание и есть «очередь»: у того, кто должен над этим РП сейчас работать, есть какая-то другая работа в процессе, а за ней еще парочка. Классически очереди работают по принципу FIFO, и в случае разработки это не оптимальный вариант.
Такие виртуальные рабочие продукты в процессе не ставятся на баланс предприятия и не видны в финансовом разрезе, поэтому финансовый аспект очередей и задержки тоже невидим.
Очереди увеличивают цикл одного рабочего продукта, время от начала работы над ним до выпуска в финальном виде.
Хочется сделать такой вывод:
нет смысла увеличивать эффективность работы над рабочими продуктами, пока мы не оптимизируем очереди.
Пример:
🟢 — работа над РП
🔴 — ожидание в очереди
Ситуация у нас такая:
🟢🟢🔴🔴🔴🔴🔴🔴🟢🟢🔴🔴🔴🔴🔴🔴🔴🟢🟢
То есть над РП работают два дня, потом он шесть дней ждет, потом еще два дня в работе, еще семь дней ждет, и наконец финальные два дня в работе перед выпуском. Итого цикл 19 дней, чистое время работы над РП 6 дней.
Допустим, мы удвоим эффективность инженеров и они смогут решить задачу в два раза быстрее — за три дня:
🟢🔴🔴🔴🔴🔴🔴🟢🔴🔴🔴🔴🔴🔴🔴🟢
Экономия: 🟢🟢🟢
Получаем цикл 16 дней. Плюс затраты на увеличение эффективности инженеров.
А теперь вместо этого сократим очереди вдвое:
🟢🟢🔴🔴🔴🟢🟢🔴🔴🔴🔴🟢🟢
Экономия: 🔴🔴🔴🔴🔴🔴
Получаем цикл 13 дней и не трогаем инженеров, пусть работают как работали.
Проблема с обнаружением очередей в разработке продукта — в «невидимости» рабочих продуктов, зависших в ожидании. В физическом производстве очередь видно глазами: перед станком лежит горка деталей на обработку. А в продуктовой разработке большая часть РП — это информационные объекты, описания, код и тому подобные артефакты. Очереди, в которых они застревают, не видны, если не знать, что они есть.
Обнаружить очереди можно по наблюдаемым последствиям: увеличенному времени цикла, отложенной обратной связи, меняющимся приоритетам и характеру докладов о статусе РП («ждем», «еще не приступили» и т. п.). Стоимость задержки увеличивается линейно в зависимости от размера очереди.
Очереди можно проиллюстрировать на Cumulative Flow Diagram:
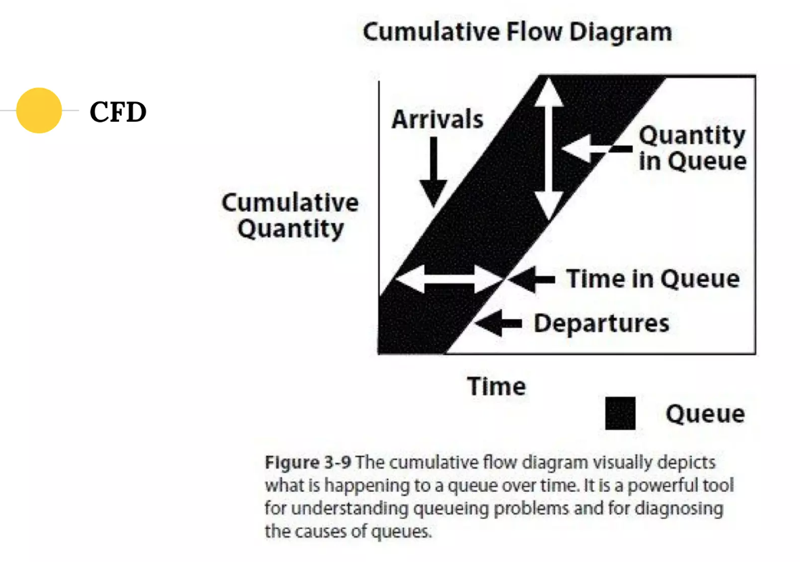
По оси X время, по оси Y размер очереди; левая наклонная Arrivals — это прибывающие (пассажиры, объекты, что угодно), точка на X это начало цикла; правая наклонная Departures — выбывающие, точка на X это конец цикла. Горизонтальная прямая от точки на Arrivals до точки на Departures — это длительность цикла. Вертикальная прямая от Departures до Arrivals — размер очереди.
Вот пример из все той же презентации The Principles of product development flow — a summary:
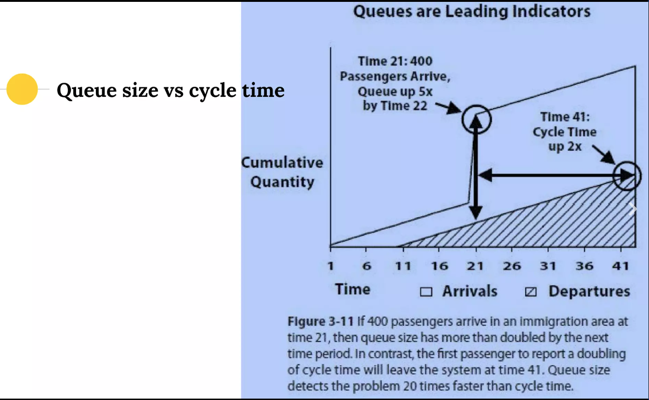
График показывает, как именно понимание очередей может предсказать проблемы на проекте по сравнению с измерением времени цикла или обратной связи.
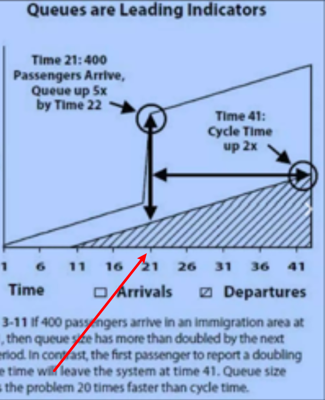
Во время 21 прибывает партия из 400 людей — и со времени 41 мы узнаем об увеличении времени цикла в 2 раза — горизонтальная стрелка, параллельная оси x, показывает нам это; при этом время увеличится еще, и мы это увидим из графика раньше, чем дождемся соответствующего человека в конце цикла.
Длительность цикла удвоилась: чтобы количество прибывших превратилось в такое же количество убывших, требуется вдвое больше времени. Как раз потому, что прибыло больше, а скорость обработки одного осталась прежней.
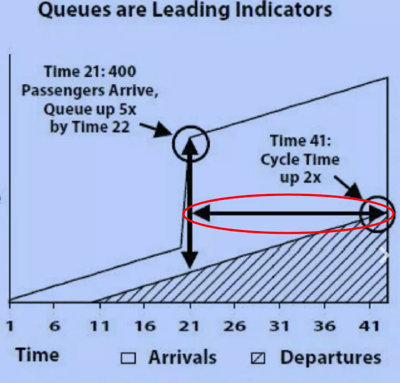
Время цикла — это прямая, параллельная горизонтали, пересекающая обе наклонные. Или время, в течение которого количество убывших стало равно количеству прибывших.
Смысл графика: если мы знаем про очереди и умеем их измерять — мы можем предсказать проблему с увеличением длительности цикла просто по факту увеличения очереди, не дожидаясь завершения цикла.
Поклонение эффективности #
Вики: «Эффекти́вность (лат. effectivus) — соотношение между достигнутым результатом и использованными ресурсами (ISO 9000:2015)»
Так сложилось, что в работе компании стараются эффективно использовать промежутки, когда идет работа над каким-то рабочим продуктом, и абсолютно игнорируют очереди, когда РП болтается без дела; отсюда
помешательство на личной эффективности, битва за продуктивность, тайм-менеджмент и т. п.
Затраты на всякие подпроцессы в разработке обычно считаются так: стоимость ресурса в ед. времени + стоимость простоя/задержки; без понимания очередей, мы не можем посчитать стоимость задержки. А раз мы не понимаем стоимость задержки — мы фокусируемся на эффективности использования ресурса.
Еще раз вспоминаем про пример сверху с шариками 🟢🔴.
Мы хотим, чтобы эффективность была высокой, и в этом своем стремлении можем достигать опасно высокого уровня загрузки ресурса.
Уровень может быть опасным, потому что при высоких уровнях утилизации ресурса неконтролируемо растут очереди.
Эффективность — это только прокси показатель, он не отражает всю экономическую картину разработки РП. Нужно уметь измерять вклад повышения эффективности на общую экономику и трейд-оффы ее повышения.
Неприятие вариабельности #
Под вариабельностью в книге понимается вероятность возникновения изменений в ходе разработки. Я сам пока не вполне эту концепцию понимаю, немного помог пример в конце параграфа.
В производстве высокая вариабельность вредит: когда нужно просто производить продукцию по спецификации, любое отклонение от плана помешает. Петров забухал и не пришел — значит, какой-то участок простаивает, работа замедляется, план под угрозой. У деталей от нового поставщика другой допуск точности — нужно переналаживать линию, это время, план под угрозой. В производстве обычно стараются сократить вариабельность, чем более предсказуемо все пойдет — тем лучше.
В разработке продукта без вариабельности не будет инноваций: если мы не будем иногда менять план и отказываться от уже принятых решений, то не сможем использовать возникающие возможности себе на пользу. Нужно допускать полезные изменения и уметь снижать влияние вредных на разработку. С другой стороны, чем выше степень вариабельности, тем больше рисков.
Сама степень вариабельности — это прокси-метрика, с точки зрения книги нас должно интересовать влияние вариабельности на экономику проекта.
В видео «Don Reinertsen — Second Generation Lean Product Development Flow» Дон приводит пример с Боингом. Если бы проект по разработке 777-го был полностью избавлен от вариабельности, то инженеры бы не взялись тестировать новый предложенный поставщиками сплав алюминия и лития — он был легче алюминия и мог сэкономить вес. Сплав в итоге не подошел, у него были проблемы с прочностью; зато подошли композиты, которые после испытаний и проверок добавили в проект. В исходной документации не было ни алюминий-литиевого сплава, ни композитов, но их обнаружение и внедрение пошло проекту на пользу.
Поклонение соответствию/конформность #
Под «конформностью» в книге подразумевается слепое следование изначальному плану.
В традиционном подходе считается, что любое отклонение от изначального плана — это плохо, и если оно случилось, нужно вернуть ситуацию на рельсы. Крайне редко кто-то прикидывает, чего это будет стоить проекту/компании, и принимает решение на основе подсчета; обычно же считают, что следование плану всегда целесообразно.
Это, однако, может быть экономически нецелесообразно и противоречит методу рационального фланера, скрывает открывающиеся возможности.
Да и сами запланированные действия могут поменять какие-то свои детали: косты, ценность.
Вывод: нужно регулярно пересматривать план и проактивно искать открывающиеся возможности. Про возможности см. пост про осознание возможностей.
Институционализация больших партий #
Большие партии → дешевле производить → больше прибыль. Это справедливо для производства, но не для разработки.
Считается, что с большими партиями снизится вариабельность. Чуть выше мы уже поняли, что понижать ее до нуля в разработке нельзя. А от больших партий она уменьшится вроде как немного, зато добавит кучу неопределенности в силу дальнего горизонта планирования. Компания станет менее гибкой на этот горизонт, т. к. под проект будут забронированы мощности, выделен страховой запас и так далее.
Другая проблема — отложенный фидбек. Чем больше партия, тем длиннее цикл, и тем дольше мы не получим фидбек. В примере с письмами из книги Эрика Риса «Бизнес с нуля» (Lean Startup в оригинале), отец с двумя дочерьми собираются разослать несколько сотен писем. На каждом письме нужно поставить печать, вложить в конверт, написать адрес, заклеить конверт. Можно начать делать все по этапам, а можно обрабатывать каждое письмо по отдельности. В этой байке победил второй вариант — работа с малыми партиями.
Дальше цитата:
«Предположим, что письма не помещаются в конверты. При работе с большими партиями мы узнаем об этом только в конце. А подход небольших партий позволит увидеть это почти сразу. Что, если конверты бракованные и не заклеиваются? При работе большими партиями нам придется вынуть письма из всех конвертов, взять новые конверты и снова вложить в них письма. Выполняя работу небольшими партиями, мы сразу увидим, что конверты бракованные, и нам не нужно будет ничего переделывать.»
Водопадное планирование подразумевает использование «фазовых ворот», когда все рабочие продукты приходят одной большой партией к следующему этапу. В примере про конверты — сначала мы все письма подписываем, и только потом приступаем к этапу «положить в конверт». Это тоже вариант работы с большими партиями.
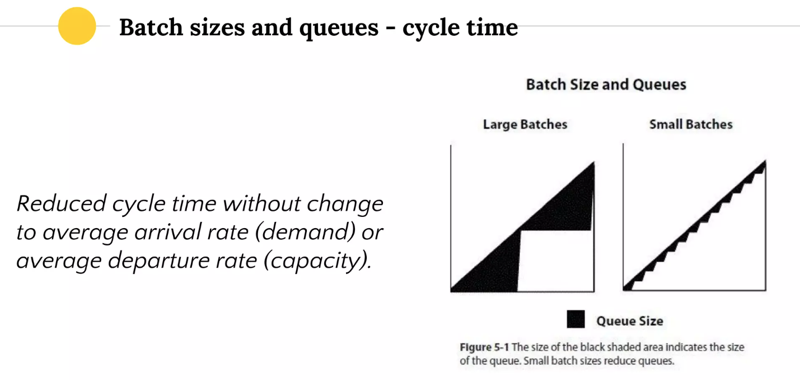
Малые партии гораздо лучше подходят для работы, но для их обеспечения нужно научиться снижать транзакционные косты.
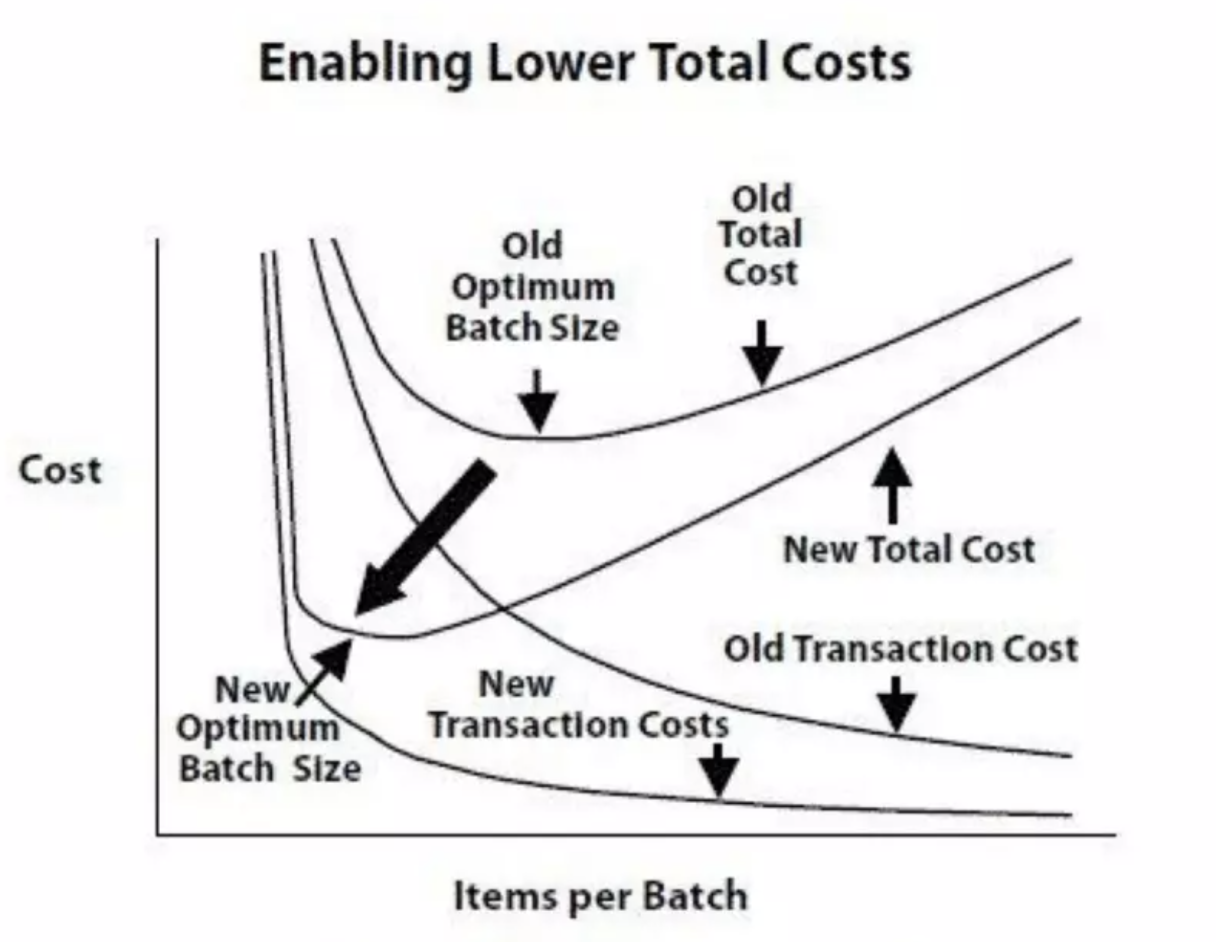
В видео «Don Reinertsen — Second Generation Lean Product Development Flow» Дон приводит такой бытовой пример: допустим, вам надоело два раза в неделю ходить и покупать яйца. Вам нужно 2-3 штуки в день, вы вычисляете, что на год вам нужно тысячу с небольшим яиц. И вот у вас есть два крайних варианта: купить яиц сразу на год, или покупать яйца два раза в неделю. В случае с яйцами на год, у вас снижаются до минимума транзакционные издержки: нужно один раз договориться с продавцом, доставить яйца домой, и все. Зато сильно повышаются издержки на хранение: придется купить второй холодильник.
Выбор правильного размера партии — это выбор правильной точки на графике пересечения издержек на хранение/поддержку и транзакционных издержек:

Про малые партии в софтверной разработке есть хорошее упражнение про правильную нарезку слона. Да и весь скрам, в общем-то, об этом.
Недоиспользование каденса/каденции #
В книге под cadence понимается регулярность чего-либо; например, встречи для ревью дизайна, или регулярные поставки версий продукта.
Пример такой: если не назначать отдельную встречу каждый раз, когда нужно провести ревью дизайна очередной партии РП, а проводить эти ревью по графику раз в неделю, то транзакционные издержки на назначение таких встреч будут минимальными, и можно выносить на ревью даже небольшое количество рабочих продуктов (=малую партию).
Управление таймлайнами, а не очередями #
Таймлайны — это временны́е аспекты задач внутри проекта. Но учитывать мы их можем только по тем периодам, когда работа делается, а очередей и простоев мы не видим.
Нужно сделать очереди видимыми, понимать их стоимость и научиться ими управлять.
Негибкость #
Придерживаемся устаревшего плана, специализируем работников, загружаем мощности до предела.
Про устаревший план выше было. А вот про специализацию работников интересное: на производствах платят больше тем сотрудникам, которые могут работать на нескольких производственных участках или станках, а не на одном.
В продуктовой же разработке (да и в софтверной) приветствуется специализация. При этом, если мы признаем, что полностью избавляться от вариабельности нельзя, то специализация в случае изменений скорее вредит, чем помогает.
Про загрузку мощностей до предела — примерно такая же ситуация. Если загрузка ресурса выше 60-70%, то резко растут очереди.
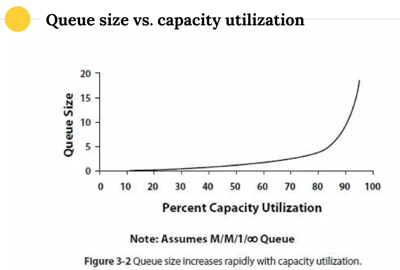
Централизованный контроль #
Упрощаем управление до прямого директивного, недоиспользуем или пропускаем новые возможности из-за централизации. Решения, которые нужно принять руководителю с полномочиями, выстраиваются в еще одну очередь.
Снова пример с Боингом-777: в какой-то момент стало понятно, что самолет не помещается в целевой вес, обещанный клиентам. Запахло миллионными штрафами, нужно было срочно облегчать самолет. Инженерам разрешили не согласовывать затраты за облегчение конструкции, если избавление от фунта веса обходилось в триста долларов или меньше. В итоге 5000 инженеров смогли принимать самостоятельные решения без согласования, руководитель программ не стал узким местом в принятии этих решений. Поскольку он все равно контролировал итоговую стоимость проекта, изменения ему были видны и он мог на них повлиять.
Пока осталось за кадром:
- Отсутствие ограничения работы в процессе (WIP) — делаем много всего одновременно, удлиняем очереди, теряем гибкость
- Не-экономический контроль потока — контролируем не по эк. метрикам, а по каким-то другим.
Продолжение: https://artemushanov.ru/?go=all/reynertsen-post-2/
Пример про очереди поучительный.